Przeglądanie agentowe to eksperymentalna kategoria audytów w Lighthouse, która sprawdza, czy strona jest czytelna i nawigowalna dla agentów AI. Pojawia się w raportach PageSpeed Insights obok znanych kategorii jak Performance czy Accessibility, ale działa inaczej. Zamiast jednego wyniku punktowego dostarcza zestaw audytów zaliczonych oraz niezaliczonych (aktualnie 3 wskaźniki).
Jest to o tyle istotne, że Lighthouse zaczyna diagnozować, czy strona jest wystarczająco czytelna, stabilna i opisana, żeby agent AI mógł się po niej poruszać bez zgadywania. Nie oznacza, że jest to oficjalny czynnik rankingowy Google, ale raczej, że jest to wyraźny krok w tym kierunku. Spodziewam się, że z aktualnych 3 wskaźników audytowych AI PageSpeed Insights wprowadzi wkrótce taką samą punktację od 1 do 100 punktów, jaką mają pozostałe kategorie audytu.
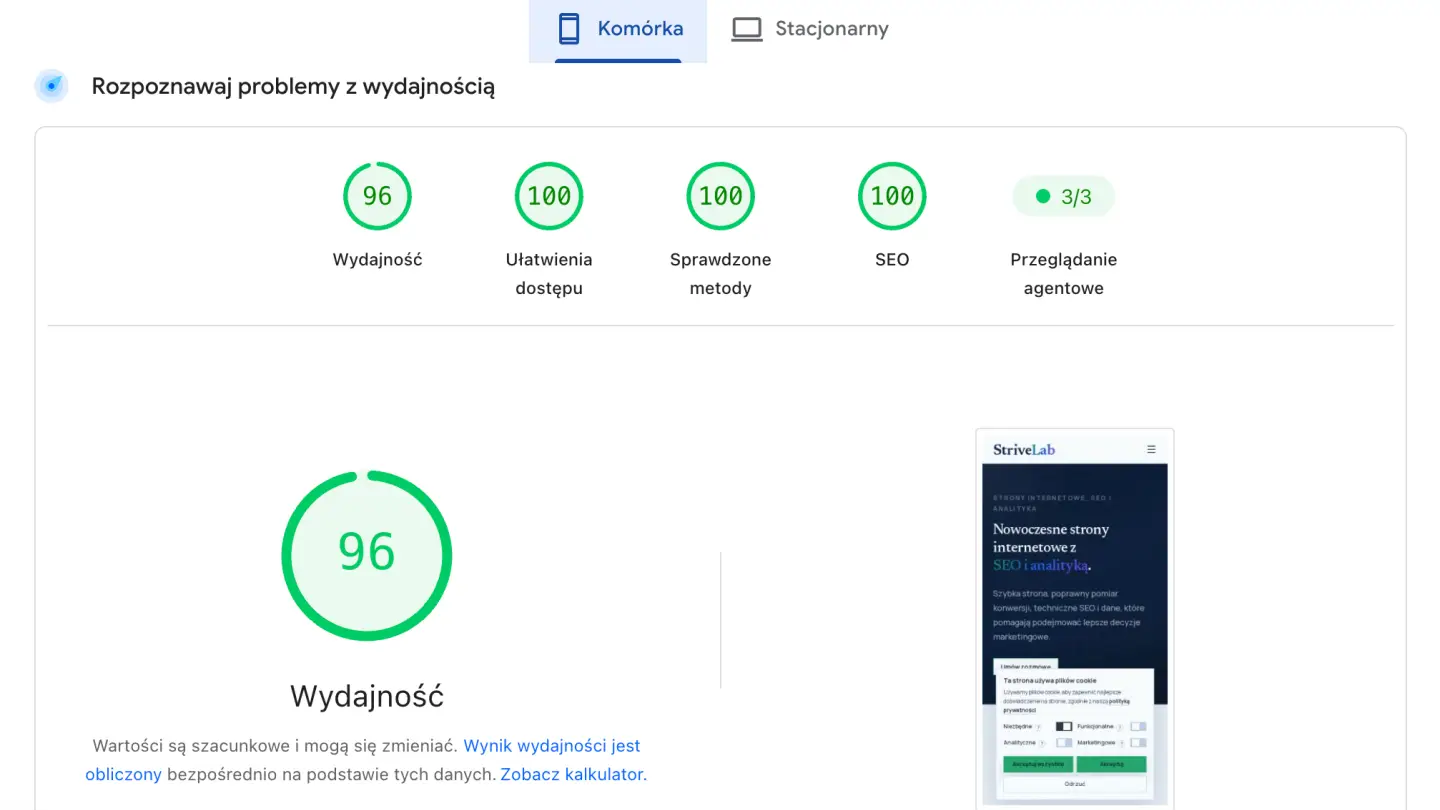
Raport dla StriveLab w PageSpeed Insights z widoczną kategorią przeglądanie agentowe.
Dlaczego strony projektowane tylko dla użytkowników tracą czytelność dla agentów AI
Strona może wyglądać świetnie dla użytkownika, ale może być jednocześnie chaosem dla poruszającego się po niej agenta AI. By się szybko pogubił, wystarczy kilka błędnych rozwiązań frontendowych. Może to być menu renderowane dopiero po hydracji, przyciski zrobione z div, formularz bez etykiet, hero przesuwające layout po załadowaniu fontu, albo treść schowana za klientowym JavaScriptem.
Użytkownik tego nie zauważy podczas korzystania ze strony, ale już dla agenta AI to utrata kontekstu, ponieważ agent nie zawsze patrzy na stronę tak jak użytkownik. Agent często korzysta z drzewa dostępności, DOM-u, tekstu, linków, semantyki i czasem ze zrzutu ekranu. Jeśli te warstwy nie mówią tego samego, agent może źle rozpoznać ofertę albo kliknąć w nie ten element. W efekcie strona może zostać pominięta albo błędnie zinterpretowana w odpowiedziach AI.
Z mojego punktu widzenia przeglądanie agentowe jest sygnałem kierunku zmian: frontend, dostępność, Core Web Vitals, llms.txt i architektura informacji zaczynają zbiegać się w jednym pytaniu: czy strona dostarcza maszynie dobry kontekst?
Co bada przeglądanie agentowe w Lighthouse i PageSpeed Insights?
W praktyce chodzi o dwa pojęcia: i .
Discoverability oznacza, czy agent potrafi odkryć, co jest na stronie ważne. Czy widzi główną treść? Czy linki prowadzą do kluczowych sekcji? Czy llms.txt podpowiada, gdzie szukać najważniejszych informacji? Czy formularz kontaktowy ma etykiety, a przycisk mówi programowo, co robi?
Navigability oznacza, czy agent potrafi po tej stronie bezpiecznie przejść i nie zgubić kontekstu. Istotne są kwestie: czy layout nie przesuwa się pod kursorem? Czy element interaktywny jest realnym <button> albo <a>, a nie dekoracyjnym kontenerem z onClick? Czy menu, formularze i karty są obecne w DOM-ie w przewidywalny sposób?
Najważniejsze sygnały są dziś proste:
— agent korzysta z nazw, ról i relacji elementów. Jeśli ikona-przycisk nie ma etykiety, człowiek może się domyślić po wyglądzie, ale agent dostaje pustą informację.
— Cumulative Layout Shift jest ważny nie tylko dla UX. Jeśli element zmienia pozycję między identyfikacją a kliknięciem, agent może trafić w złe miejsce.
llms.txt— plik w roocie domeny daje agentom krótki, maszynowo czytelny indeks najważniejszych treści.— eksperymentalna warstwa opisu akcji i narzędzi w przeglądarce. Ważna kierunkowo, ale jeszcze nie jest obowiązkowym wdrożeniem dla każdej strony.
Checklist SEO: jak przygotować stronę pod przeglądanie agentowe i agentów AI
Pierwszym krokiem powinno być zrobienie porządku w rzeczach, które od lat są podstawą dobrego frontendu, dostępności oraz technicznego SEO.
Semantyczny HTML i struktura DOM dla agentów AI
Agent AI czyta strukturę strony, dlatego potrzebujemy klasycznego, semantycznego HTML:
- Używaj
<main>,<nav>,<article>,<section>,<aside>zgodnie z przeznaczeniem - Buduj interakcje na
<button>i<a href>, nie na klikalnychdiv-ach - Każdy element interaktywny musi mieć programową nazwę: tekst,
aria-labelalbo poprawnie powiązany<label> - Trzymaj logiczną hierarchię nagłówków i opisowe anchor texty
- Nie ukrywaj kluczowej treści przez
aria-hidden, karuzele bez fallbacku albo komponenty istniejące dopiero po hydracji
W React najczęstszy problem jest z komponentami współdzielonymi: jeden źle napisany IconButton, CardLink albo customowy Select potrafi masowo zepsuć dostępność np. na kilkunastu podstronach naraz.
Plik llms.txt jako mapa strony dla agentów AI
llms.txt nie jest nowym robots.txt, który komunikuje reguły crawlowania. llms.txt daje agentowi skrócony przewodnik po stronie: kim jesteś, co oferujesz i które URL-e są najważniejsze. Szczegółowy format, przykłady dla Next.js i Astro oraz zasady utrzymania opisałem w osobnym poradniku o wdrożeniu pliku llms.txt.
Minimalna struktura jest zamierzona i obejmuje H1, krótki opis w blockquote oraz listy linków w Markdownie. Dla małej strony możesz zacząć od statycznego pliku, ale w blogu albo serwisie z CMS lepiej generować go z tego samego źródła prawdy co sitemapę. W sytuacji, kiedy sitemapę tworzysz automatycznie, a llms.txt aktualizujesz ręcznie, oba pliki szybko się rozjadą. Tego unikaj.
Przykład minimalnego kształtu:
Nie wrzucaj do llms.txt wszystkiego, tylko linkuj strony kanoniczne, publiczne, aktualne i te warte pokazania agentowi. Pełne przykłady endpointów, filtrowanie draft/noindex, llms-full.txt i różnice między Astro a Next.js zostawiam w poradniku wdrożeniowym, bo tutaj najważniejsze jest zrozumienie, dlaczego llms.txt jest jednym z sygnałów gotowości strony dla agentów.
Nagłówki llms.txt: jak nie zepsuć Performance, optymalizując pod agentów
Tutaj omówię problem o którym łatwo zapomnieć. Surowy plik tekstowy wgrany bez konfiguracji potrafi obniżyć wynik Performance, bo PageSpeed Insights zgłosi „Enable text compression" i „Serve static assets with an efficient cache policy". Czyli przypadkowo, podczas optymalizacji strony pod agentów, możemy obniżyć Core Web Vitals. Tego nie chcemy i by tego uniknąć llms.txt powinien być kompresowany i mieć rozsądny Cache-Control oraz jawne kodowanie UTF-8.
W Next.js z App Routerze najczystszym rozwiązaniem jest serwowanie llms.txt jako route i ustawienie nagłówków w next.config.mjs. Kompresją zajmuje się wtedy hosting albo wbudowany compress, a Ty kontrolujesz cache i Content-Type:
max-age trzymam krótko dla przeglądarki, a s-maxage dłużej dla CDN, żeby plik realnie cache'ował się na brzegu, ale agent dalej widział aktualne treści. Na Vercelu kompresja Brotli/Gzip dla text/plain działa automatycznie, więc nie musisz jej ręcznie włączać. To samo na Astro osiągniesz nagłówkami w vercel.json albo w konfiguracji hostingu. Jeśli zostajesz na Apache, ten sam rezultat daje mod_deflate/mod_brotli dla text/plain w .htaccess.
W efekcie plik waży ułamek pierwotnego rozmiaru, ma poprawne kodowanie polskich znaków i nie generuje czerwonych ostrzeżeń w raporcie wydajności.
JavaScript, SSR i hydracja: jak ograniczyć szum dla agentów AI
Agenty AI nie przepadają za stronami, które są puste bez JavaScriptu, ciężkie po hydracji i niestabilne wizualnie. To oznacza w praktyce, że treść i nawigacja nie powinny zależeć wyłącznie od klientowego runtime'u.
- SSR/SSG dla treści, która ma być odkrywalna.
- Server Components tam, gdzie nie ma realnej interakcji.
- Małe Client Components zamiast całych sekcji oznaczonych
"use client". - Brak lazy-loadu dla kluczowej treści tekstowej.
- Rezerwacja miejsca na obrazy, embedy, cookie bary i dynamiczne bloki.
- Ograniczenie third-party scripts, które opóźniają interakcję i zmieniają layout.
Najgorszy wariant to strona, która po pobraniu HTML-a pokazuje tylko pusty root aplikacji, a właściwa oferta, menu i CTA pojawiają się dopiero po hydracji. Dla użytkownika na szybkim laptopie to może być niezauważalne. Dla części agentów i prostych crawlerów to nadal pusta strona.
WebMCP w przeglądaniu agentowym: kiedy ma sens, a kiedy jest za wcześnie
jest ważny, ale trzeba go opisać precyzyjnie. To nie jest to samo co klasyczny używany przez Cursor, Claude Desktop czy własne integracje z CMS-em. O tym drugim piszę osobno w artykule o Model Context Protocol w TypeScript.
W kontekście Lighthouse WebMCP dotyczy strony w przeglądarce: formularzy, akcji i narzędzi, które agent mógłby rozpoznać bez zgadywania po wyglądzie. Przykładowo, może to być formularz kontaktowy opisany tak, żeby agent wiedział, jakie dane wpisać i co się stanie po wysłaniu.
Jak przetestować przeglądanie agentowe i gotowość strony dla agentów AI?
Aktualnie nie istnieje jeden „AI-ready score", dlatego najlepiej połączyć ze sobą kilka prostych testów.
PageSpeed Insights i Lighthouse. Sprawdź, czy przeglądanie agentowe pojawia się w raporcie i które audyty są oznaczone jako zaliczone, oblane albo informacyjne. Lokalnie możesz użyć CLI:
Accessibility tree. W Chrome DevTools sprawdź nazwy i role najważniejszych elementów: menu, CTA, formularzy, kart usług, przycisków ikonowych. W sytuacji, jeśli użytkownik widzi przycisk, a accessibility tree widzi pusty element, agent również dostaje słaby sygnał.
Playwright jako smoke test semantyki. W CI nie musisz robić testów pod AI, ale możesz testować warunki, których agent potrzebuje:
Manualny test z modelem. Może być pożyteczny, by wyłapać niektóre problemy. Po prostu wklej agentowi HTML strony albo link i poproś: „Znajdź najważniejszą ofertę, formularz kontaktowy i najnowszy artykuł", a jeśli model gubi się w nawigacji, myli CTA albo nie potrafi wskazać kluczowej treści, problem najprawdopodobniej nie jest związany z AI, ale ze strukturą strony.
Logi i crawling bez JS. Możesz też sprawdzić, co widzi prosty crawler bez renderowania JavaScriptu. Jeżeli bez JS znikają menu, oferta, dane autora i linki wewnętrzne, to masz problem nie tylko z przeglądaniem agentowym, ale także z technicznym SEO.
Logi serwera zamiast GA4. Warto pamiętać, że klasyczna analityka tego ruchu nie pokaże i to z przyczyn technicznych. Dzieje się tak, ponieważ GA4 ładuje się przez JavaScript, a spora część agentów i prostych crawlerów AI nie uruchamia skryptów. W efekcie nie odpali kodu śledzącego. Jeśli chcesz wiedzieć, czy agenci faktycznie odpytują llms.txt i które podstrony skanują, zejdź do logów serwera (panel hostingu, log access lub dedykowane narzędzie). Aktualnie to najpewniejszy sposób, żeby zobaczyć, kto i jak często czyta Twój kontekst dla maszyn.
Dlaczego strona czytelna dla agentów AI daje przewagę biznesową?
Coraz więcej ścieżek zakupowych zaczyna się od prośby i użytkownik nie wpisuje już tylko „agencja Next.js Kraków", ale pyta asystenta: „znajdź mi wykonawcę szybkiej strony usługowej w Astro albo Next.js, który ogarnia SEO techniczne". Jest to o tyle istotne, że intencja przechodzi z 4-5 słów kluczowych w bardzo konkretne, długie zapytanie brzmiące jak mała opowieść. Widać to na przykładzie Google Search Console, gdzie w raporcie zapytań pojawia się coraz więcej bardzo długich, konwersacyjnych fraz.
Agent przetwarza dostępny kontekst: treść, strukturę, linki, dane autora, semantykę, llms.txt, dostępność oraz stabilność interfejsu.
Jeśli Twoja strona jest czytelna dla maszyn, wyraźnie zmniejszasz ryzyko, że agent pominie Twoją stronę, bo nie umie zrozumieć oferty albo znaleźć właściwej podstrony. W ten sposób techniczna czytelność strony staje się częścią dystrybucji. Witryna ma nie tylko wyglądać atrakcyjnie, ale także musi być łatwa do zacytowania, streszczenia i użycia. Ostatecznie mamy więc kolejną warstwę jakości.
Kontekst jako usługa: przyszłość SEO dla agentów AI
Zamiast optymalizować stronę pod algorytm AI, wpadać w sztuczne checklisty, składać przesadne obietnice i pisać treści bardziej pod narzędzie niż pod człowieka, lepiej zacząć od przyjęcia innego modelu myślenia o problemie.
Myśląc w kierunku, mówię tutaj o kontekście jako usłudze (z ang. ), w którym twoja strona ma dostarczać kontekst różnym odbiorcom. Najważniejsi są użytkownicy, którzy chcą szybko zrozumieć ofertę/produkt, ponieważ to oni decydują, czy oferta zamienia się w realny biznes. Poza tym odbiorcą jest twój zespół, który utrzymuje treść, sitemapę, schema i llms.txt z jednego źródła prawdy. Do tego dochodzi Googlebot, który musi zindeksować treść oraz agent AI, który ma ją streścić, porównać albo wykonać akcję.
Każdy z tych odbiorców potrzebuje semantycznego HTML, stabilnego layoutu, dostępnej nawigacji, SSR/SSG, dobrych danych strukturalnych i llms.txt. Właśnie te fundamenty pomagają jednocześnie ludziom, wyszukiwarkom i agentom.
Jeśli chcesz sprawdzić, czy Twój stack jest gotowy na ten model — React, Next.js, Astro, llms.txt, accessibility tree, CLS i renderowanie treści — napisz do mnie. Audyt AI-first powinien kończyć się listą konkretnych poprawek w kodzie.



